1.论文下载地址
https://cs.stanford.edu/~matei/papers/2018/sigmod_structured_streaming.pdf
2.前言
建议首先阅读Structured Streaming官网:http://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
以及这两篇Databricks在2016年关于Structured Streaming的文章:
https://databricks.com/blog/2016/07/28/structured-streaming-in-apache-spark.html
言归正传
该论文收录自2018年ACM SIGMOD会议,是由美国计算机协会(ACM)发起的、在数据库领域具有最高学术地位的国际性学术会议。论文的作者为Databricks的工程师及Spark的开发者,其权威性、重要程度不言而喻。文章开头为该论文的下载地址,供读者阅读交流。本文对该论文进行简要的总结,希望大家能够下载原文细细品读,了解最前沿的大数据技术。
3.论文简要总结
题目:Structured Streaming: A Declarative API for Real-Time Applications in Apache Spark
3.1 摘要
摘要是一篇论文的精髓,这里给出摘要完整的翻译。
随着实时数据的普遍存在,我们需要可扩展的、易用的、易于集成的流式处理系统。结构化流是基于我们对Spark Streaming的经验开发出来的高级别的Spark流式API。结构化流与其他现有的流式API,如谷歌的Dataflow,主要有两点不同。第一,它是一个基于自动增量化的关系型查询API,无需用户自己构建DAG;第二,结构化流旨在于支持端到端的实时应用并整合流与批处理的交互分析。在实践中,我们发现这种整合是一个关键的挑战。结构化流通过Spark SQL的代码生成引擎实现了很高的性能,是Apache Flink的两倍以及Apache Kafka的90倍。它还提供了丰富的运行特性,如回滚、代码更新以及流/批混合执行。最后我们描述了系统的设计以及部署在Databricks几百个生产节点的一个用例。
3.2 流式处理面临的挑战
(1) 复杂、低级别的API
(2) 端到端应用的集成
(3) 运行时挑战:容灾,代码更新,监控等
(4) 成本和性能挑战
3.3 结构化流基本概念
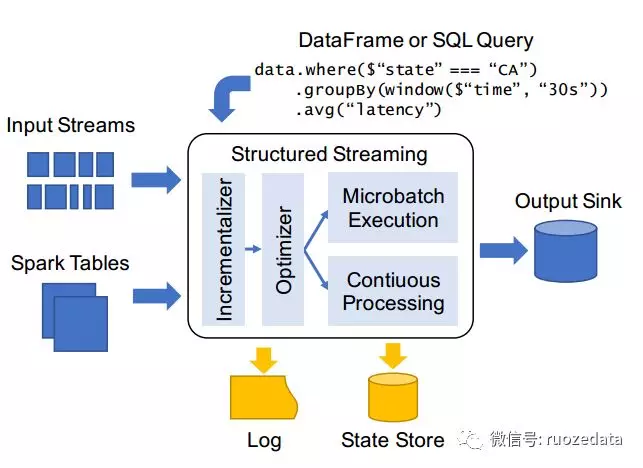
图1 结构化流的组成部分
(1) Input and Output
Input sources 必须是 replayable 的,支持节点宕机后从当前输入继续读取。例如:Apache Kinesis和Apache Kafka。
Output sinks 必须支持 idempotent (幂等),确保在节点宕机时可靠的恢复。
(2) APIs
编写结构化流程序时,可以使用Spark SQL的APIs:DataFrame和SQL来查询streams和tables,该查询定义了一个output table(输出表),用来接收来自steam的数据。engine决定如何计算并将输出表 incrementally(增量地)写入sink。不同的sinks支持不同的output modes(输出模式,后面会提到)。
为了处理流式数据,结构化流还增加了一些APIs与已有的Spark SQL API相配合:
- a. Triggers 控制engine多久执行一次计算
- b. event time 是数据源的时间戳;watermark 策略,与event time 相差一段时间后不再接收数据。
- c.Stateful operator(状态算子),类似于Spark Streaming 的updateStateByKey。
(3) 执行
一旦接收到了查询,结构化流就会进行优化递增,并开始执行。结构化流使用两种持久化存储的方式实现容错:
- a.write-ahead log (WAL:预写日志)持续追踪哪些数据已被执行,确保数据的可靠写入。
- b.系统采用大规模的 state store(状态存储)来保存长时间运行的聚合算子的算子状态快照。
3.4 编程模型
结构化流将谷歌的Dataflow、增量查询和Spark Streaming 结合起来,以便在Spark SQL下实现流式处理。
- a. A Short Example
首先从一个批处理作业开始,统计一个web应用在不同国家的点击数。假设输入数据是一个JSON文件,输出一个Parquet文件,该作业可以通过DataFrame来完成:1
2
3
4
5
61// Define a DataFrame to read from static data
2data = spark . read . format (" json "). load ("/in")
3// Transform it to compute a result
4counts = data . groupBy ($" country "). count ()
5// Write to a static data sink
6counts . write . format (" parquet "). save ("/ counts ")
把该作业变成使用结构化流仅仅需要改变输入和输出源,例如,如果新的JSON文件continually(持续地)上传,我们只需要改变第一行和最后一行。
1 | 1// Define a DataFrame to read streaming data |
结构化流也支持 windowing(窗口)和通过Spark SQL已存在的聚合算子处理event time。例如:我们可以通过修改中间的代码,计算1小时的滑动窗口,每五分钟前进一次:
1 | 1// Count events by windows on the " time " field |
- b. 编程模型语义
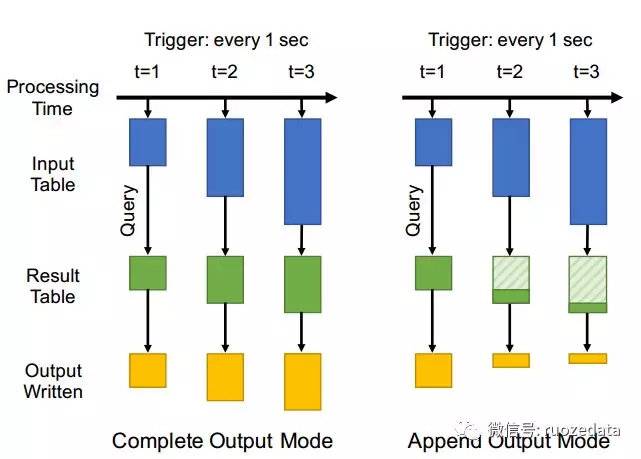
图 2 两种输出模式
- i. 每一个输入源提供了一个基于时间的部分有序的记录集(set of records),例如,Kafka将流式数据分为各自有序的partitions。
- ii. 用户提供跨输入数据执行的查询,该输入数据可以在任意给定的处理时间点输出一个 result table(结果表)。结构化流总会产生与所有输入源的数据的前缀上(prefix of the data in all input sources)查询相一致的结果。
- iii. Triggers 告诉系统何时去运行一个新的增量计算,何时更新result table。例如,在微批处理模式,用户希望会每分钟触发一次增量计算。
- iiii. engine支持三种output mode:
c.流式算子Complete:engine一次写所有result table。 Append:engine仅仅向sink增加记录。 Update:engine基于key更新每一个record,更新值改变的keys。 该模型有两个特性:第一,结果表的内容独立于输出模式。第二,该模型具有很强的语义一致性,被称为prefix consistency。加入了两种类型的算子:watermarking算子告诉系统何时关闭event time window和输出结果;结构化流允许用户通过withWatermark算子来设置一个watermark,该算子给系统设置一个给定时间戳C的延迟阈值tC,在任意时间点,C的watermark是max(C)-tC。 stateful operators允许用户编写自定义逻辑来实现复杂的功能。1
2
3
4
5
6
7
8
9
10
11
12
13
141// Define an update function that simply tracks the
2// number of events for each key as its state , returns
3// that as its result , and times out keys after 30 min.
4def updateFunc (key: UserId , newValues : Iterator [ Event ],
5state : GroupState [Int ]): Int = {
6val totalEvents = state .get () + newValues . size ()
7state . update ( totalEvents )
8state . setTimeoutDuration ("30 min")
9return totalEvents
10}
11// Use this update function on a stream , returning a
12// new table lens that contains the session lengths .
13lens = events . groupByKey ( event => event . userId )
14. mapGroupsWithState ( updateFunc )
用mapGroupWithState算子来追踪每个会话的事件数量,30分钟后关闭会话。
3.5 运行特性
(1) 代码更新(code update)
开发者能够在编程过程中更新UDF,并且可以简单的重启以使用新版本的代码。
(2) 手动回滚(manual rollback)
有时在用户发现之前,程序会输出错误的结果,因此回滚至关重要。结构化流很容易定位问题所在。同时手动回滚与前面提到的prefix consistency有很好的交互。
(3) 流式和批次混合处理
这是结构化流最显而易见的好处,用户能够共用流式处理和批处理作业的代码。
(4) 监控
结构化流使用Spark已有的API和结构化日志来报告信息,例如处理过的记录数量,跨网络的字节数等。这些接口被Spark开发者所熟知,并易于连接到不同的UI工具。
3.6 生产用例与总结
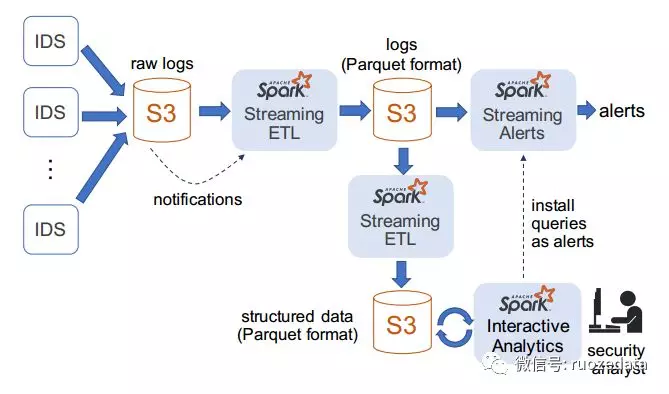
给出简要架构图,篇幅原因不再赘述,希望详细了解的下载论文自行阅读。本文只挑选了部分关键点进行了浅层次的叙述,希望读者能够将论文下载下来认真品读,搞懂开发者的开发思路,跟上大数据的前沿步伐。